Applies to:
PDFTextStream
Extracting text from PDF documents
PDFTextStream provides two ways to extract text from PDF documents:
- The
com.snowtide.pdf.OutputHandlerinterface and its included implementations direct extracted text at the document, page, or block level to files and in-memory buffers, while optionally applying arbitrary formatting logic. - PDFTextStream provides a traversable document model corresponding to the content found on each page of a PDF; it can be traversed directly to selectively access and extract content based on arbitrary application and business logic
Most applications will use the former, and PDFTextStream ships with a
number of OutputHandler
implementations designed to satisfy common text extraction use cases.
The most
commonly-used OutputHandler is
com.snowtide.pdf.OutputTarget. It extracts all
text from the document, page, or block being piped as efficiently as
possible, aiming to produce content that is in a natural read-ordering
suitable for content-oriented processing (such as indexing and search,
summarization, and dictation purposes). Here's an example showing
OutputTarget in use; in general,
aside from minor points of configuration,
all OutputHandler usage follows the
same pattern:
public String getPDFText (File pdfFile) throws IOException {
Document pdf = PDF.open(pdfFile);
StringWriter buffer = new StringWriter();
stream.pipe(new OutputTarget(buffer));
stream.close();
return buffer.toString();
}
When a pipe(OutputHandler) method is invoked, all of the
content held by the object being piped is sent (in document-model order) to
the OutputHandler, which can
decide what content should or should not be included in the resulting
extract, and what formatting should be applied to
it. The OutputHandler interface
essentially defines
a visitor
pattern over the domain of the PDFTextStream document model, making
implementing custom formatting and extraction strategies very
straightforward; see here for details.
pipe(OutputHandler) methods are available at all levels of the
PDFTextStream document model:
- Document:
com.snowtide.pdf.Document.pipe(OutputHandler) - Page:
com.snowtide.pdf.Page.pipe(OutputHandler) - Block:
com.snowtide.pdf.layout.Block.pipe(OutputHandler) - Line:
com.snowtide.pdf.layout.Line.pipe(OutputHandler)
So in the above example, invoking
the Document.pipe(com.snowtide.pdf.OutputHandler)
method sends the entire document's content to
the OutputHandler. Piping a
block to an OutputHandler will
yield only that block's content, and so on.
OutputHandler's can generally
write text content to any java.lang.Appendable, which
includes java.nio.CharBuffers
and java.io.Writers. This makes many use cases very easy to
implement, such as sending extracted PDF text directly to a local file,
which is done here for a single page:
public void savePDFText (File pdfFile, int pageNumber, File textFile) throws IOException {
Document pdf = PDF.open(pdfFile);
Page page = pdf.getPage(pageNumber);
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(textFile)));
page.pipe(new OutputTarget(writer));
pdf.close();
writer.flush();
writer.close();
}The PDFTextStream Document Model
PDF documents specify their textual content one character at a time, without any indication of physical structure (such as lines, blocks, columns, etc) or logical organization (headers, paragraphs, captions, footers, etc). Therefore, PDFTextStream must employ advanced document understanding processes to derive the structure of each PDF document page it is presented. These processes gather characters into lines, lines into blocks, blocks into columns, and so on. The document structure that these entities represent and the API that PDFTextStream exposes for developers to work with them collectively forms the PDFTextStream document model.
The document model is necessarily hierarchical, and its API mirrors that hierarchy:
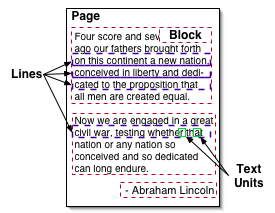
com.snowtide.pdf.Pages
contain com.snowtide.pdf.layout.Blocks.
Blocks may contain
other Blocks
or com.snowtide.pdf.layout.Lines (but not
both). Lines
contain com.snowtide.pdf.layout.TextUnits which
roughly represent single characters.
This structure is rooted at the page-level by an object that implements the
com.snowtide.pdf.layout.BlockParent interface,
available via
com.snowtide.pdf.Page.getTextContent(). Objects
that implement the
BlockParent interface
contain an ordered set
of Blocks, each of which
represent a block of text presented on a page within a PDF document. In most
circumstances, each Block
instance corresponds to a paragraph of text.
Blocks,
Lines, and
TextUnits all implement
the com.snowtide.pdf.layout.Bounded interface,
meaning that each provides
a com.snowtide.pdf.layout.Bounded.bounds() method
that returns a bounding box rectangle object allowing for the retrieval of
their positioning on the page (x- and y-coordinates, height, width,
etc.). Additionally, Blocks
also implement
the BlockParent
interface, which means
that BlockParents can
contain
other BlockParents. This
is necessitated by document structures such as tables, where distinct blocks
of content must be grouped and ordered together. Use
the API reference to find the particulars of how
to traverse the document model – each document model entity presents a very
simple list-like API that should be essentially self-explanatory.
TextUnit Details
To anyone who does not know the inner workings of PDF documents and how fonts and encodings work in the PDF document specification, "text unit" might seem to be a strange diversion from the straightforward names given to the other parts of the PDFTextStream document model ("page", "block", "line", and so on). It is worth exploring why these entities are called "TextUnits" and not simply "Characters".
A quick look at the javadoc
of TextUnitcom.snowtide.pdf.layout.TextUnit
reveals a few interesting
methods: com.snowtide.pdf.layout.TextUnit.getCharacterSequence()
and
com.snowtide.pdf.layout.TextUnit.getCharCode(). Text
in PDF documents is encoded as a series of character codes (available
via TextUnit.getCharCode()),
which are then mapped to a concrete sequence of Unicode characters
(available via
TextUnit.getCharacterSequence())
based on the encoding that is specified by a PDF document. That sounds
straightforward enough until one realizes that PDF documents can encode more
than one Unicode character for each individual raw character code.
For example, a PDF document might specify that the character code 188 should be mapped to the Unicode (and ASCII) character ‘f’. However, it could specify instead that the character code 189 should be mapped to a sequence of Unicode characters, such as "fi" or "ae". Therefore, each TextUnit instance can represent an indeterminate number of Unicode characters.
Please note that the font in effect when each TextUnit is outputted is
available via com.snowtide.pdf.layout.TextUnit.getFont().
OutputHandlers: Text Extraction using Document Model Events
In many applications, simple text extraction as shown in the above sections
is not enough to meet requirements. Sometimes a PDF document is so large
that extracting all of its text would strain your application’s available
resources. Perhaps your application needs to produce something other than
plain text, such as an HTML version of the PDF document. The best way to
meet such requirements is to utilize
the OutputHandler interface.
The OutputHandler interface is
directly analogous to the lightweight SAX
XML ContentHandler interface. Just like XML, PDFTextStream
defines a document model that can be traversed systematically using a
random-access interface (which is called DOM in the XML world). But also
just like XML, PDFTextStream provides a way to process document content in a
lightweight, evented
fashion. The OutputHandler
interface represents this second option. It defines a range of methods
that can be selectively implemented to, for example, only be notified of
character-level
data. An OutputHandler subclass
that does this by overriding
the com.snowtide.pdf.OutputHandler#textUnit(com.snowtide.pdf.layout.TextUnit)
function will receive one event (in the form of a TextUnit
object) for every TextUnit object in a given PDF document page
or block. The OutputHandler
subclass can then take whatever action is necessary given its purpose –
write the TextUnit’s
content to disk, send it over a network connection, make note of where
the TextUnit is located
on the page for display purposes, and so on.
Each com.snowtide.pdf.Document, Page,
and Block instance
provides a pipe(OutputHandler) function. Invoking this function
on any instance of these classes will cause the appropriate PDF document
model events to be sent to the
provided OutputHandler object in
the natural order that they occur. For example, just before starting the
events associated with a block of
content, com.snowtide.pdf.OutputHandler.startBlock(Block)
will be called with
that Block instance as a
parameter; when all of the child entities of
that Block have been
delivered (its child blocks, its child lines, its
child TextUnits, etc),
com.snowtide.pdf.OutputHandler.endBlock(Block)
will be called. Events bookend content like this for all of the containers
in the PDFTextStream document model: the PDF document itself
(com.snowtide.pdf.OutputHandler.startPDF(java.lang.String,
java.io.File)
and com.snowtide.pdf.OutputHandler.endPDF(java.lang.String,
java.io.File)), pages
(com.snowtide.pdf.OutputHandler.startPage(Page)
and com.snowtide.pdf.OutputHandler.endPage(Page)),
blocks (as has already been discussed), and lines
(com.snowtide.pdf.OutputHandler.startLine(Line)
and com.snowtide.pdf.OutputHandler.endLine(Line)).
Source code for example OutputHandler implementations are
included with your PDFTextStream distribution. The pdfts.examples.GoogleHTMLOutputHandler
sample will produce an XHTML document that roughly duplicates the spirit of
the "view as text" page that Google provides for PDF search results. Another
OutputHandler example, pdfts.examples.XMLOutputTarget,
writes an XML document directly to a provided StringBuffer that
includes structural document information, as well as indications of text
formatting (e.g. bolding, underlining, strikethroughs, italics, etc.).
Finally, a .NET-specific OutputHandler implementation example
can be found here.