Extracting tables from PDF documents
One of the most common reasons why software teams adopt PDFxStream is the tools it provides for extracting tabular data from PDF documents.
The specifics of how this is done depends upon how the tables you are interested in are rendered in your source PDF documents. Keeping in mind that, internally, PDF documents are described entirely visually and not structurally (i.e. there is no information in PDF that e.g. some content constitutes a heading, while some other content constitutes a table row), there are in general two broad categories of table rendering:
- Explicit tables, where table structures (rows and
columns) are laid out using visible graphical lines:
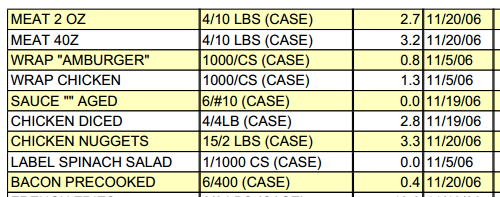
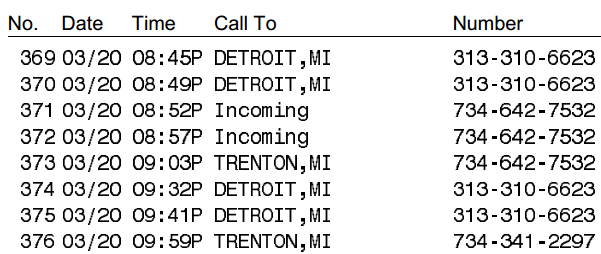
- Implicit tables, where table structures (rows and
columns) are only distinguished using patterns of whitespace:
These examples will be used throughout this page to demonstrate how PDFxStream supports the extraction of data from both kinds of tables.
Extracting data from explicit tables
The visible graphical lines used to render explicit tables gives
PDFxStream a ton of information about how to split tables into rows and
columns. This identification is fast and entirely automatic, and
produces com.snowtide.pdf.layout.Table objects (a subtype of
the common com.snowtide.pdf.layout.Block class) within the
document model PDFxStream provides for each
com.snowtide.pdf.Page.
Accessing the data that's been re-structured into those
Table objects can be done in a few
different ways. We'll go through all of them, starting with the most
flexible (and thus, complicated), and moving through to more convenient
turnkey approaches.
"Manually" walking the document model
As you traverse the document model tree (starting from the root
available via com.snowtide.pdf.Page.getTextContent()), you can
check each child Block to see if it is
a Table; for each table, you can then
use its methods to access each row (containing a series of
Blocks, one per cell within a row).
This approach requires more code and is somewhat more complex than the
next example, but it does give you the opportunity to
fine-tune exactly which tables to extract (e.g. you could only extract
those that are on the lower half of a page, or have a particular heading
above them).
For example, this code will extract only the first column of data from
the first table found on a given Page:
private static List<String> getFirstColumnData (Table t) throws IOException {
ArrayList<String> columnData = new ArrayList<String>();
for (int i = 0; i < t.getRowCnt(); i++) {
BlockParent row = t.getRow(i);
if (row.getChildCnt() > 0) {
Block cell = row.getChild(0);
StringBuilder sb = new StringBuilder();
OutputTarget tgt = new OutputTarget(sb);
cell.pipe(tgt);
columnData.add(sb.toString());
}
}
return columnData;
}
private static List<String> getFirstTableData (BlockParent bp) throws IOException {
for (int i = 0; i < bp.getChildCnt(); i++) {
Block b = bp.getChild(i);
if (b instanceof Table) {
return getFirstColumnData((Table)b);
} else if (b instanceof BlockParent) {
List<String> data = getFirstTableData((BlockParent)b);
if (data != null) return data;
} else {
// leaf non-table block, nothing to do
}
}
return null;
}
private static List<String> getFirstTableData (Page p) throws IOException {
return getFirstTableData(p.getTextContent());
}
public static void main (String[] args) throws IOException {
Document pdf = com.snowtide.PDF.open("/path/to/file.pdf");
System.out.println(getFirstTableData(pdf.getPage(0)));
}
Applying the code above to a page containing some explicitly-rendered
table(s) will properly return the data in the first column in the first
table as a list of Strings:
> [MEAT 2 OZ, MEAT 40Z, WRAP "AMBURGER", WRAP CHICKEN, SAUCE "" AGED,
CHICKEN DICED, CHICKEN NUGGETS, LABEL SPINACH SALAD, BACON PRECOOKED]
Using TableUtils makes extracting explicit table data easy
Much easier than manually walking around the PDFxStream document model
is using the com.snowtide.pdf.util.TableUtils class and its
collection of convenient methods for comprehensively capturing
explicitly-rendered table data. The example presented above can be
replaced using TableUtils with this much
shorter, simpler code:
private static List<String> getFirstTableData (Page p) throws IOException {
List<Table> tables = TableUtils.getAllTables(p);
if (tables.size() == 0) {
return null;
} else {
String[][] firstTable = TableUtils.tableToStrings(tables.get(0));
ArrayList<String> firstColumn = new ArrayList<String>();
for (String[] row : firstTable) {
if (row.length > 0) firstColumn.add(row[0]);
}
return firstColumn;
}
}
public static void main (String[] args) throws IOException {
Document pdf = com.snowtide.PDF.open("/path/to/file.pdf");
System.out.println(getFirstTableData(pdf.getPage(0)));
}
As an added bonus for those that need to "export" PDF tables to Excel,
Google Sheets, or any other downstream program or process that can work
well with CSV data,
com.snowtide.pdf.util.TableUtils.convertToCSV(Table, char)
is a convenient table-to-CSV export method that's so easy, you can dump
e.g. the first table on the first page to CSV with a single expression:
TableUtils.convertToCSV(TableUtils.getAllTables(pdf.getPage(0)).get(0), ',');
"MEAT 2 OZ","4/10 LBS (CASE)","2.7","11/20/06","1.0","11.2","","10.2","",""
"MEAT 40Z","4/10 LBS (CASE)","3.2","11/20/06","-0.1","24.2","","24.2","",""
"WRAP ""AMBURGER""","1000/CS (CASE)","0.8","11/5/06","2.7","1.4","","0.0","",""
"WRAP CHICKEN","1000/CS (CASE)","1.3","11/5/06","2.2","0.8","","0.0","",""
"SAUCE """" AGED","6/#10 (CASE)","0.0","11/19/06","0.0","0.0","","0.0","",""
"CHICKEN DICED","4/4LB (CASE)","2.8","11/19/06","2.3","2.1","","0.0","",""
"CHICKEN NUGGETS","15/2 LBS (CASE)","3.3","11/20/06","1.3","15.2","","13.8","",""
"LABEL SPINACH SALAD","1/1000 CS (CASE)","0.0","11/5/06","0.0","0.6","","0.6","",""
"BACON PRECOOKED","6/400 (CASE)","0.4","11/20/06","0.2","1.6","","1.4","",""
Extracting data from implicit tables
In contrast to explicit tables that use visible lines to demarcate the beginning and end of rows and columns, implicit tables rely on lanes and other patterns of whitespace to convey the impression of tabular structure:
Searching for PDF content arranged to suit the kinds of whitespace
patterns associated with tabular data cannot reasonably be performed
automatically: while there are very reliable ways to identify table
structure using implicit whitespace, they are too computationally costly
to include in the page segmentation and document model PDFxStream builds
for each Page. So, for implicit tables, we
recommend extracting them as text using
com.snowtide.pdf.VisualOutputTarget, and using familiar
text-processing utilities to break the resulting text up into rows and
columns.
VisualOutputTarget is an alternative
com.snowtide.pdf.OutputHandler implementation that is included
in PDFxStream that aims to retain the visual layout of the document's
content as accurately as possible, using plain text spaces and
linebreaks to simulate the precise spatial positioning of each character
in the source PDF. (See 'Controlling the formatting of extracted
text' for more about
VisualOutputTarget.) Thus,
VisualOutputTarget produces text extracts
where the whitespace separating table columns and rows are usefully
reproduced in plain text.
Here is example VisualOutputTarget output for
the implicit table shown above:
369 03/20 08:45P DETROIT,MI 313-310-6623
370 03/20 08:49P DETROIT,MI 313-310-6623
371 03/20 08:52P Incoming 734-642-7532
372 03/20 08:57P Incoming 734-642-7532
373 03/20 09:03P TRENTON,MI 734-642-7532
374 03/20 09:32P DETROIT,MI 313-310-6623
375 03/20 09:41P DETROIT,MI 313-310-6623
376 03/20 09:59P TRENTON,MI 734-341-2297
Tabular text extracts like this can be sliced and diced quite easily
using standard-library tools like regular expressions and textual
pattern matching libraries, as well as common Unix standbys like cut
and awk.