Indexing PDF documents with Lucene and PDFTextStream
Apache Lucene is a full-text search engine written in Java. It is a perfect choice for applications that need 'built-in' search functionality: it's fast, works well with any kind of document structure, and is relatively painless to build around.
Lucene is focused on text indexing, and as such, it does not natively handle popular document formats such as Word, PDF, HTML, etc. Rather, it requires the use of external tools or libraries to convert any such documents into collections of text fields, which can then be easily indexed.
If you're not familiar with how Lucene works, please refer to the Lucene project's documentation.
The PDFTextStream includes an easy to use API for integrating it with Lucene, versions 1.2 and later. After setting some configuration parameters, you can easily generate a collection of text fields that Lucene needs for indexing purposes given a PDF file.
Since Lucene by itself will accept and process only plain text, some kind of adapter must be used that can extract plain text from PDF files in order for those files' content to be added to a Lucene index. PDFTextStream goes one step further than just extracting text from PDF files to be used with Lucene – it provides a complete set of Lucene integration classes that enables a Lucene user to easily add PDF document content to Lucene indexes. Conceptually, how PDFTextStream and its integration classes relate to Lucene is shown here:
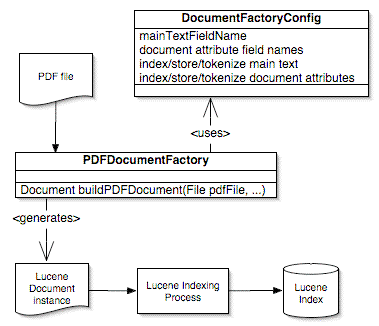
Two PDFTextStream classes provide the Lucene integration functionality: com.snowtide.pdf.lucene.PDFDocumentFactory and com.snowtide.pdf.lucene.DocumentFactoryConfig.
Using these classes is very straightforward:
- A
DocumentFactoryConfiginstance is created and configured. This configuration determines how Lucene will index a PDF file processed by PDFTextStream (i.e. what fields will be indexed, tokenized, and/or stored), and what names will be assigned to the various fields that will make up the index record (called aDocumentin Lucene parlance). - That
DocumentFactoryConfiginstance is passed along with a PDF file (or PDF file data in the form of ajava.io.InputStream) into one of the staticbuildPDFDocument()methods provided by thePDFDocumentFactoryclass. - The
PDFDocumentFactory.buildPDFDocument()method returns aorg.apache.lucene.document.Documentinstance. The LuceneDocumentclass represents a single record in the Lucene index to which it is added. The LuceneDocumentinstances that are created by thePDFDocumentFactory.buildPDFDocument()methods derive their fields' contents from the text and metadata attributes extracted from the source PDF file by PDFTextStream, and their field names and index attributes (whether to store, index, and/or tokenize each field's contents) from the configuration held by theDocumentFactoryConfiginstance that was created in the first step. - Once a Lucene
Documentinstance is obtained from thePDFDocumentFactoryclass, it can be passed directly into Lucene's indexing process (typically via aorg.apache.lucene.index.IndexWriterobject), which will add theDocumentto an open index.
It's a wonderful thing when the code needed to do something is shorter than the space needed to explain all that it does for you. Here's some heavily-commented example code that does everything described above using a sample PDF file and Lucene index:
import java.io.*;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.document.Document;
import com.snowtide.pdf.PDFTextStream;
public class EasyLuceneIntegration {
/**
* Simple method that adds the contents of the provided PDF document to the
* Lucene index via an already-open Lucene IndexWriter.
*/
public static void addPDFToIndex (IndexWriter openIndex, File pdfFile)
throws IOException {
// create and configure new DocumentFactoryConfig instance
DocumentFactoryConfig config = new DocumentFactoryConfig();
// set the name to be used for the main body of text extracted from the
// PDF file, and set it to not be stored, but to be tokenized and indexed
config.setMainTextFieldName("body_text");
config.setTextSettings(false, true, true);
// only copy the PDF metadata attributes into Lucene Document instances
// produced by PDFDocumentFactory that we explicitly map
// via DocumentFactoryConfig.setFieldName()
config.setCopyAllPDFAttrs(false);
// cause PDF metadata attribute values to be stored, tokenized, and indexed
config.setPDFAttrSettings(true, true, true);
// Explicitly set the names that should be used for the fields that are
// created in the Lucene Document instance -- otherwise, default PDF
// names will be used that will likely not be picked up when the index
// is searched.
// For example, the default name for the modification date
// field in PDF files is 'ModDate', but our example Lucene index stores
// the modification dates of Documents with the name 'mod_date'. The
// third setFieldName() call below establishes the correct mapping.
config.setFieldName(PDFTextStream.ATTR_AUTHOR, "creator");
config.setFieldName(PDFTextStream.ATTR_CREATION_DATE, "creation_date");
config.setFieldName(PDFTextStream.ATTR_MOD_DATE, "mod_date");
// actually generate the Lucene Document instance from the PDF file
// using the configuration we've just built, and add the Document to the
// Lucene index
Document doc = PDFDocumentFactory.buildPDFDocument(pdfFile, config);
openIndex.addDocument(doc);
}
}
Customizing Lucene Document fields
Unless a DocumentFactoryConfig
instance is provided in the call to one of the buildPDFDocument() methods,
the fields in the created Lucene Documents take on the defaults
provided by the PDF file. For example, the default name of the creation date
attribute included in the metadata of some PDF files is CreationDate,
so that will be the name assigned to the field in the Lucene Document
that contains the value of that attribute. The actual text content of a PDF
file will be added to the Lucene Document as a field with the
name defined in com.snowtide.pdf.lucene.DocumentFactoryConfig.DEFAULT_MAIN_TEXT_FIELD_NAME.
Allowing these default names to be used for the fields in each Lucene
Document is convenient, but is probably not what you want; few Lucene
indexes will have used those defaults when being built. In order to
seamlessly integrate PDFTextStream into your Lucene installation, you will
want to customize how the Document instances are built. For
this, you should use DocumentFactoryConfig.
Typically, a single DocumentFactoryConfig
instance will be created and configured for each Lucene index that PDF
content needs to be added to.
The main body of text contained in a PDF file is stored in a Lucene Document
object as just another named field. This name defaults to the value defined
by DocumentFactoryConfig.DEFAULT_MAIN_TEXT_FIELD_NAME,
but can be set either via the DocumentFactoryConfig
constructor, or by a setter method on a DocumentFactoryConfig
instance.
By default, all of the document metadata found in PDF files processed by PDFDocumentFactory will be copied into fields in
the resulting Lucene Documents. However, in many circumstances, only a
subset of the metadata attributes contained in a PDF file will be relevant
to the index to which its content will be added. In this case, you can
change this property to false, allowing only those PDF file
attributes that have been explicitly mapped via com.snowtide.pdf.lucene.DocumentFactoryConfig.setFieldName(java.lang.String,
java.lang.String) to be added to the Lucene Document instances.
Also, the names used to identify the extracted metadata attributes can be customized. For example, a PDF file might contain these attributes:
| Attribute Name | Attribute Value |
Creator |
Microsoft Word |
Author |
Kate Burneson |
CreationDate |
Mar 30, 2002 08:12:44 AM -0800 |
Using the default attribute names is likely not appropriate if this example
PDF file's content is to be added to a Lucene index that has, for example,
document author fields named authored_by and creation time/date
stamps named create_dt. The default field names can be mapped
to their desired replacements easily, using the DocumentFactoryConfig.setFieldName(java.lang.String, method:
DocumentFactoryConfig config = new DocumentFactoryConfig(); config.setFieldName(PDFTextStream.ATTR_AUTHOR, "authored_by"); config.setFieldName(PDFTextStream.ATTR_CREATION_DATE, "create_dt");
This will cause any invocation of a PDFDocumentFactory.buildPDFDocument()
method that uses the config object to build Lucene Document
instances that use the name authored_by for any Author
PDF metadata attribute, and create_dt for any CreationDate
attribute. Note that the most common PDF document attributes have
standardized names, which are fixed as static final constants in the
PDFTextStream class. All such constant fields in the PDFTextStream class
have an ATTR prefix to identify them as standard document
attribute names.
Storing vs. Indexing vs. Tokenizing
Fields in every Lucene document have three attributes associated with them,
typically referred to as store, index, and token.
These attributes control how Lucene processes each field when it is added to
an index as a part of a Document instance (a full discussion of these
attributes and how they impact Lucene indexing and searching is beyond the
scope of this guide; please refer to Lucene's documentation for more
information).
The values to be used for store, index, and token
when creating named fields in Lucene Documents can be set for
PDF document attributes via com.snowtide.pdf.lucene.DocumentFactoryConfig.setPDFAttrSettings(boolean,
boolean, boolean). The values provided to this method are used for all
fields created for PDF document attributes. All of these settings default to
true.
The values for store, index, and token
for the main body of text read out of PDF files can be set via com.snowtide.pdf.lucene.DocumentFactoryConfig.setTextSettings(boolean,
boolean, boolean). The defaults for these settings are false,
true, and true, respectively.
Fin
It should be clear now that PDFTextStream provides remarkably easy-to-use Lucene integration, and one that will readily scale in the most demanding of Lucene-based indexing environments (given PDFTextStream's core performance characteristics). The conceptual overview and code sample provided in here should get you most of the way towards making Lucene play nice with PDF documents thanks to PDFTextStream, much to the benefit of your applications and projects.