Accessing PDF bookmarks
Some PDF documents contain bookmarks (sometimes referred to collectively as a "document outline") that refer to significant document sections. If a document contains bookmarks, they appear in the ‘Bookmarks’ panel in Adobe Reader, forming an interactive table of contents for the document:

PDFxStream allows you to access the bookmarks contained in PDF documents and all of the attributes associated with those bookmarks.
Bookmark structure and attributes
PDF bookmarks are organized into a tree structure with a single root node.
If a PDF document contains bookmarks, that root node is returned by
the com.snowtide.pdf.Document.getBookmarks() method as
a com.snowtide.pdf.Bookmark instance. Each
bookmark may contain child bookmarks, accessible using
the com.snowtide.pdf.Bookmark.getChildCnt()
and com.snowtide.pdf.Bookmark.getChild(int) methods; entire branches of the
bookmark tree can also be easily retrieved using
the com.snowtide.pdf.Bookmark.getAllDescendants()
and com.snowtide.pdf.Bookmark.getAllDescendants(List) methods.
Bookmarks have two main attributes: a title (the text that describes the
section to which the bookmark refers) and a page number. These attributes
are accessible using
the com.snowtide.pdf.Bookmark.getTitle() and
the com.snowtide.pdf.Bookmark.getPageNumber()
methods. All leaf nodes in the bookmark tree should have a
page number defined, and many branch nodes may specify a page number as
well. It is common for the root node of the bookmark tree to define neither
a page number or title. In that case,
the Bookmark.getTitle() method
will return null, and
the Bookmark.getPageNumber()
method will return -1.
Precise Bookmark Positioning
In addition to the page number, some bookmarks will provide specific spatial
coordinates, defining where on the target page a PDF viewer should position
its viewing window when a user activates a bookmark. These functions
(com.snowtide.pdf.Bookmark.getTopBound(),
com.snowtide.pdf.Bookmark.getLeftBound(), com.snowtide.pdf.Bookmark.getRightBound(),
and com.snowtide.pdf.Bookmark.getBottomBound())
return those coordinates. Many bookmarks will specify only some coordinates,
in which case a PDF viewer would orient its viewing window along the defined
coordinates, and simply show all of the remaining portions of the target
page.
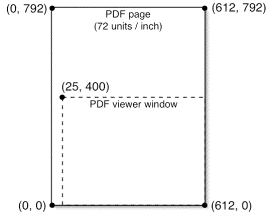
For example, a bookmark referring to page 12 might specify a top bound
of 400, a left bound of 25, and undefined right
and bottom bounds (values of -1). A PDF viewer would therefore
position its viewing window like so:
Having this level of precision available can be very useful, especially when requirements specify the extraction of text from only particular sections of a document. This tutorial demonstrates how to extract only a particular section of text from a document based on the precise coordinate bounds specified by a PDF document’s bookmarks.